Branches, builds and modern data pipelines. Let's catch-up!


It's been a long while since my last blog. Bows head in shame Blogging is one of those things I know I should do more often, but I'm still not in the routine in which one needs to be in order to do it regularly. As a consequence, what usually happens is that I don't blog for a while, and then I write a monolithic blog which isn't ideal for the reader.
There are even remains of blog posts that "weren't to be", scattered in and amongst my OneNote notes. Every now and then I get a gentle prod from Howard. I reassure him I have everything under control (with regards to blogging) and then I never produce the goods. Wait – I'm not painting a great picture of myself here, am I? (Please don't fire me.)
The truth is, I'm never stuck for things to do. Blogging has borne the brunt of my priority prejudices, often giving way for other items on my backlog that I feel are more pressing. It's quite silly really. Correction: I'm quite silly. My backlog of 'non-urgent things to do' quite literally comprises of instructions along the lines of "Learn x", "Learn y". "Find out how z works". "Solve the P vs NP problem". I suppose that's fine, but how will I ever find time to write if that's the case?
There are always things I want to learn, and there always will be.
I need to realize that blogging in this manner isn't an obligation, nor an hindrance. It serves a totally different purpose to the tasks on my backlog, but is still a very important part of my growth and learning. It helps with my creative and reflective skills, and serves to be a point of reference for future Ed. If its content serves to be a point of reference for others, then brilliant.
This shan't be a monolithic post. You've all blessed me with your presence because of your interest in my development - the least I can do is provide you with something relatively short, sharp, and semi-enjoyable to read. I know I very much struggle to read things in which I'm not engaged, so I'd be a hypocrite if I were to make you endure something similar.
I just thought I'd talk through some of what I've been up to recently, along with a number of things I've learned along the way.
A lot has happened since my last post. Too much to list. The most notable news is that endjin is now fully remote (how many recent grads work from home full-time?) I won't go into this, but don't fret – we have it all under control, and can all still engage in real human interaction without the help of Slack. News that comes a very close second to that is our recruitment of 2 new people.
I say half, since a previous colleague has chosen to return after travelling the world, which is great news (and proves endjin is as desirable a company to work for as I have portrayed in prior posts!) Read Carmel's most recent blog here.
Jon George joined a couple of months ago; make sure you also check out his post here. One of the most brilliant things about being in my position as apprentice, is that everyone (and I mean everyone) is a mentor. Maybe not by name, but certainly by virtue. A wealth of knowledge into which I can tap - more knowledge than my brain can handle most of the time.
What have I been up to?
Since Christmas or so, I've mainly been involved in a project which has been around implementing The Modern Data Platform within a large financial organisation. The high-level view of the solution is that we receive files in a Data Lake Store, and upon receiving these files we automatically trigger a data pipeline (based on the file date and folder in which the file lives) which: extracts the subset of desired features from an xml file, outputs a virtual dataset, converts this dataset into a csv file, inserts this csv file elsewhere in the data lake store and then copies the csv file into an Azure SQL Database.
And pretty much all of this is done in the cloud! Service Bus and Azure Functions are used in conjunction to log and trigger events, but I shan't go into detail about these. Instead, I'll talk about the data analytics part of the process.
Azure Data Lake is an integral part of this pipeline – not only providing ample storage for the multitude of files arriving, but also providing the analytics behind extracting the required features from the xml file (by calling a custom C# extractor), converting to csv and inserting the file in the desired destination.
It does all this through Table-Valued-Functions written in U-SQL (a C# and T-SQL hybrid), and each these TVFs is effectively acting as an API by abstracting away the underlying storage, structure and versioning. The output file path is stated with a structured, common taxonomy (based on the date which the file arrives in the lake) which ensures discoverability, isolation and the option to apply folder-level permissions for security (in case certain teams should only be able to view a certain subset of files).
This organized folder structure allows for specific files for specific dates to be returned easily by passing in the desired date window as a parameter into the TVF. Late arrivals of files can also be addressed: the TVF can query over a time period and a WHERE clause can be added, so that if a particular file arrives a few days late, it can still be found in and amongst the more recent files.
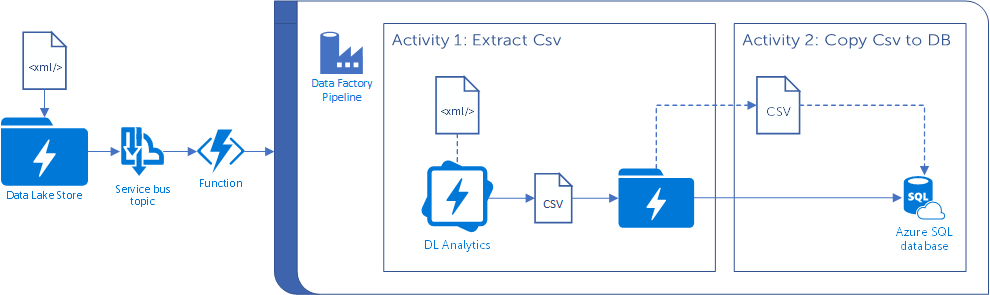
Another important tool in this pipeline is Data Factory (v2). Data Factory is effectively a job orchestrator. It can automatically perform these jobs on the click of a button, on a regular schedule, or can be triggered by an event (e.g. a file arriving in a certain location). The latter is what we have implemented in our solution. If a file arrives in a particular location, then the corresponding pipeline is automatically triggered and your U-SQL jobs and data factory 'csv-to-SQL Server' copy activities are run without any manual intervention. Pretty cool. Unless, of course, the pipeline fails. Then it's just annoying.
What else?
Possibly the most valuable, erm, 'stuff' I've learned over the past number of months is 'stuff' to do with software development and DevOps. No, I'm not yet a programming guru by any stretch of the imagination. I'm getting a good feel for clean design patterns (having methods that serve a single purpose and layering these methods rather than having a huge messy method, for example).
Abstraction and encapsulation are good things. Sensible naming conventions are paramount. Effectively, I'm getting used to the basics of the basics, but you've gotta start somewhere, right? Learning from the get-go by following good practices, however unimportant they may seem, will undoubtedly help me in the long run.
Version control seems like such a simple thing, but if you have numerous developers all working on the same solution simultaneously, pushing up branches left, right and centre - things get very confusing, very quickly, for a beginner like me. I'm just getting used to the process of pulling down 'master' before starting on a new feature, creating a new branch for that feature, finishing it (with passing tests, of course!), staging changes, committing changes, pushing changes up to the server and eventually creating a pull request.
There have been times where I've forgotten to commit changes before switching branches or forgotten to pull master before creating a branch, and ultimately paid the price with merge conflicts further down the line. Sometimes, though, merge conflicts are unavoidable. One then has to decide whether merging or rebasing is the better option. A choice that I don't like making in case I break things... But I'm getting braver!
Then there are builds and releases. Once approved, PRs get merged into master - validated that everything's good to go by a build and tests. Once verified, a particular build can be released to whatever environments one has set up. I've been clicking the buttons that set off builds and releases, and the buttons that promote releases from one environment to another. I guess the next step to set up release definitions which is a little more complicated. Maybe by the time of my next blog, I'll probably be able to enlighten you all about what I've learned about creating release definitions.
It's not all 1s and 0s
Aside from the technical aspects of the last few months, I'm learning more each day about how to be an effective consultant. This mainly comes from watching my colleagues (particularly Jess, with whom I've been working closely during the aforementioned project). One of the most important skills a consultant can have is listening. A lot of the time consultants just need to be sounding boards. Of course, expert advice should always be at the ready, but it's not always what the client needs - often it's just validation they're after.
I've been given the chance to temporarily head up client comms, attend on-site client meetings, attend client social events. All of this is building my relationship with them, building trust and affability. A positive client-consultant relationship is critical for a project's success.
I think that's where I'm going to wrap up this blog. After all, I promised a blog that wasn't so large! I've really enjoyed the past few months (in particular) at endjin. My main focus up until Christmas-or-so since I first joined endjin (in 2016) was mainly on topics related to Data Science - a direction which played to my strengths in certain respects.
More 'traditional' software development is a welcome addition to my list of experiences during this apprenticeship, and since that is the background from which most of the endjineers have come, I think I'm in the right hands.