Overflowing with dataflow part 2: TPL Dataflow

Edit: In case you missed it! Here's a link to part 1, a general overview of dataflow as a processing technique!
The specific implementation of dataflow that I want to talk about is the TPL dataflow library. The task parallel library is a .NET library which aims to make parallel processing and concurrency simpler to work with. The TPL dataflow library is specifically aimed at making parallel data processing more understandable via a pipeline-based model.
It is built up as follows:
Blocks
The dataflow is made up of data blocks. The main types of blocks I shall be talking about in this blog are the execution blocks, these are the ones I used in the aforementioned project and are the key pieces which are used in a pipeline for processing.
Each block has an internal buffer on the input, which it will read data from. When data is sent down a link, it joins the queue on the input of the target block, until it can be processed. If the processing is not being done in parallel, the queue will be processed in order. A method is passed to each block on construction (usually in the form of a lambda), and this is the method which will execute when the block is activated. The form of this lambda depends on the type of the block. Alongside the lambda, there is a constructor overload which accepts some configurable options.
There are three pre-defined types of execution block:
Propagator blocks
These derive from the class: IPropagatorBlock<TInput, TOutput>
These take an input and do some kind of process or transformation and output the result. They take a Func<Tin, Tout> as a constructor argument.
TransformManyBlock
This block fans the out the input into many outputs. For example, if you pass in a list, the block will output each member of that list individually. These will travel down any links and form a queue in the target block's internal buffer.
TransformBlock
This performs some action on the input and outputs the result, to be passed on to a further block. For example, when passed an input which is to be written to a file, this could be transformed to the desired format for writing.
Target blocks
These derive from the class: ITargetBlock<TInput>
These take an input and do something with it. They do not have an output, so in some respects can be seen as the end of a pipeline. They take an Action<Tin> as a constructor argument.
ActionBlock
Each time data appears on an action block's input executes the Action type method which it has been supplied with. E.g. writes it out to the console, or a file (note for file writing, a locking mechanism would be required if data is being processed in parallel so that multiple file writes are not attempted at once).
There are also options which can be set when constructing the blocks. For example, a block's MaxDegreeOfParallelism can be set, which tells the block whether you want the processing to be done in parallel or not. If you set this to Environment.ProcessorCount then the processing will be done using the maximum amount of hardware threads available. This means that on machines with multiple processors, data can be processed more quickly. This value can also be set to higher than the number of hardware threads, which can increase throughput. However, the option which yields the best performance is case specific so it can be helpful to run some tests to establish the best value to use.
As mentioned in my previous blog, it is recommended that immutable data is used. This eliminates issues around concurrent writing/reading of memory. However, this is not always possible and if there is shared state which is being modified/read by multiple threads, then this raises issues with concurrency which need to be thought about when designing your program. There are also other considerations, such as writing to files, which need to be thought about in the case of parallel processing.
Another configurable option is to set the option SingleProducerConstrained to true. This tells the block that it is only going to be used by one producer at any time, i.e. only one thread will be posting data to it's input. This eliminates the need for concurrency considerations in writing to the internal buffer, and can therefore dramatically decrease overhead. It is recommended that this option is used wherever possible as it can cause a marked improvement in processing speed (note, even when data processing is being done in parallel by the previous block, the data travelling down a single link will all be written to the target's internal buffer by a single thread so this option can still be used).
Another option (which can be set for all blocks, not just execution) is to set the internal buffer size for the block. By default execution blocks' buffers are unbounded, but by setting the BoundedCapacity, you can change this. Set to -1 to replicate the unbounded version, otherwise the value must be >= 1.
Finally, you have the option of specifying a scheduler when creating a dataflow block. This is set through the TaskScheduler option. This can be useful if for example you have some processes which cannot run in parallel to one another (like file writes). In that case you could define a ConcurrentExclusiveSchedulerPair, and for each block you could define whether it should use the ConcurrentScheduler or the ExclusiveScheduler, depending on whether that block can be run in parallel with other tasks using that scheduler.
Links
Once you've built all your constituent blocks, these need to be linked together. This is done using the LinkTo() method. This is a simple way to connect a block's output to another's input. If multiple blocks' inputs are connected to the same output, the data is sent to the blocks in the order that they were connected. If the data is accepted by the first block it will not be sent to the second, and so on.
In this way, you can set up conditional processing of data. An overload of the LinkTo() method also accepts a predicate, which must return true for the data to be accepted. If not accepted, then it will be passed on to the next block to have been linked up. One thing to be careful of is that messages are processed in order, so if a message is not accepted by any of the linked blocks then the program will block. To account for this it is good practice to link up a NullTarget<T> block after the conditional blocks, which will discard any unprocessed messages.
There are also a couple of options which can be set when linking up blocks:
You can set the MaxMessages that a block will process in its lifetime, any messages after this value will be rejected. You can also use the Append=false option to prepend a block to the start of the processing order, instead of adding it to the end.
Finally, there is an option to PropagateCompletion down the links, this means that when the first block is completed, a signal will be sent to the second block alerting it of this, and so on.
We now have a set of linked up blocks, configured and ready for data processing!
Processing
But, I hear you asking, how do we set off the dataflow?? How are things processed using this?? Please, give me more dataflow related information!!
Well, your wish is my command…
There are three options for starting off processing with dataflow, which are just different techniques of sending data to the start of the pipeline (after all, we have established that it is the data that actually starts the execution).
The first two are called directly from your code:
The Post() method does exactly as it says on the tin. It posts data to the block's input. The method returns a Boolean signifying whether or not the data was accepted. There are a few reasons for data being rejected. Firstly, the block could have been completed, i.e. told not to accept any more data. Another is that the internal buffer could be at capacity. This is not an issue if you are using the default unbounded buffer. However, it is important to note that if data is rejected, it will not be automatically retried, the rejection will have to be detected and the retry implemented manually.
The other option is SendAsync(). Unlike with Post(), SendAsync() will wait for the block to accept/reject the data. The data may still be rejected, e.g. if the block has been completed, but instead of being rejected if the buffer is full, it will instead wait for space to become available. So, in a scenario with bounded internal buffers, SendAsync() is the preferable option unless you don't care about possible loss of data.
The Complete() method tells the block not to receive any more data, it is used is used to notify a block that the last of the requests has been received. Therefore, any data sent after this method has been called will be rejected.
Finally, you can await Completion of a block to wait until the block has finished processing data. This will only happen once the block has been completed and it knows that there is no more data incoming.
Well, time to put these blocks together in an example.
This is the output from one run of the program, the lists are processed in parallel so are output in a random order.

And just for good measure, here's one more diagram representing the dataflow!
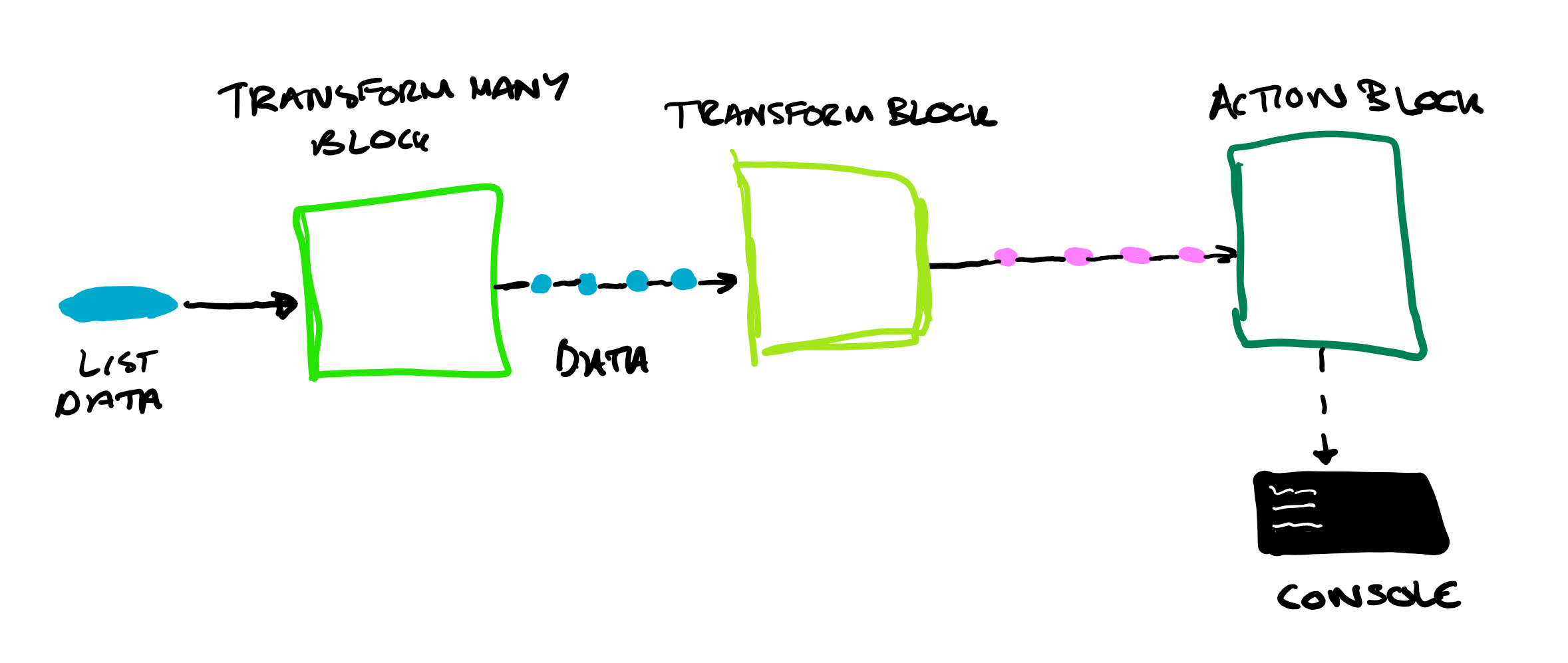
And there we have it, a simple example of data being processed in parallel using TPL dataflow! If you want to a more in depth view of the library, check out Mark Carkci's book on the subject, along with Howard's blog in which he transferred the examples into LinqPad. Look out for my next blog on the other block types in TPL dataflow, and perhaps another one on some more complex processing that can be done... (In case you haven't realised by now, I quite like this subject). Also, here's a link to my Github repository in case you want to try it out yourself!