Understanding the Stack and Heap in C#

Based on my reading, "the stack" and "the heap" are clearly important concepts for understanding how memory is managed in C# programs, however until recently I had only a superficial understanding of them and their role. This post aims to explain what the stack and heap are, and particularly their relevance to C# programs.
What is "the stack"?
"The stack" refers to the call stack, which is an implementation of the stack data structure. There are two different levels to explaining the stack: first there is the generic stack data structure, then there is the call stack, which is intrinsic to the C# runtime.
Let's first understand the stack data structure and then see how the call stack implements the data structure for performing its function in memory management.
The stack data structure
The defining property of stacks is that they're last-in, first-out, meaning the last item added to the stack is the first item to be removed. In other words, to place a new item onto a stack it has to go on the top, and only the item currently at the top can be removed, therefore if you wanted to remove an item from the middle of a stack, say, the third item down from the top, you would first have to remove the top two items.
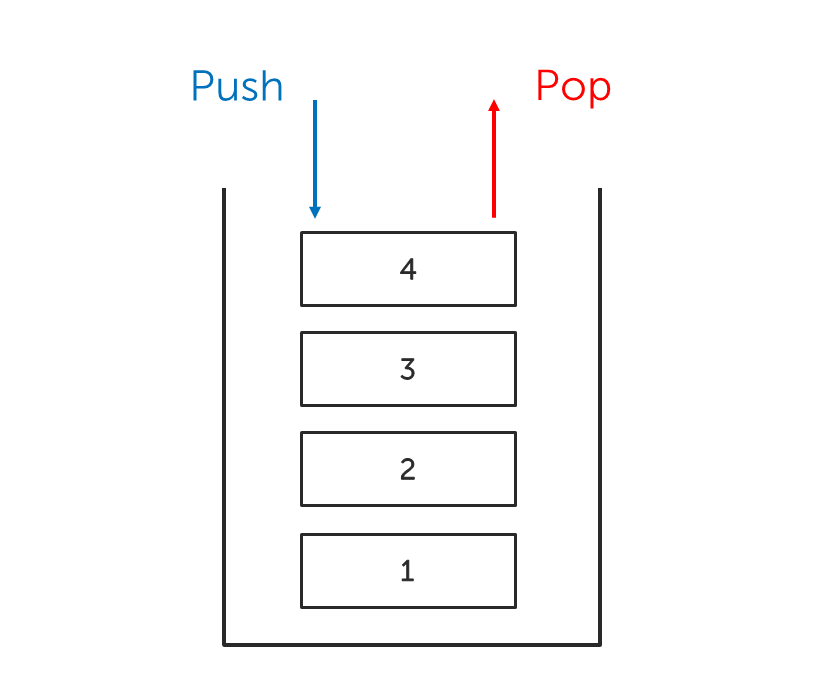
A stack of plates is a good analogy for understanding the stack data structure – to get a plate you must take one from the top (pop), to add a plate you must add it to the top of the stack (push). The stack is a simple data structure and its two operations – push and pop – are fast and efficient.
The stack (i.e. the call stack)
Again, the call stack is an implementation of a stack and is an intrinsic part of the C# runtime; it is an important component in the memory management of C# programs.
The stack has two main purposes: (1) to keep track of the method that control should return to once the currently executing method has finished, (2) to hold the values of local variables (i.e. the variables that are not needed once their containing method finishes executing).
As local variables are declared inside a method they're pushed onto the stack (just like I described for the generic stack data structure). The local variables pertaining to a given method are grouped together in what's called a stack frame; when a method finishes executing, the corresponding stack frame is popped from the stack, meaning all of the variables contained within are removed together and become unavailable. This results in the stack frame from the previous method being at the top of the stack, and, consequently, the local variables it contains being in scope – this is how variable scope is managed in C#. The examples and their associated diagrams shown later will help to understand this process.
What is "the heap"?
"The heap" refers to the managed heap, which, like the stack, plays an important (but different) role in the memory management of C# programs. The heap is an intrinsic part of the C# runtime and is an implementation of a heap data structure.
The heap data structure
There are different strategies for implementing a heap data structure, for the purposes of this blog post we can state some general properties that are relevant to this discussion…
Whereas the stack only allows items to be added and removed to/from the top, any item in a heap can be accessed at any time. This additional flexibility of the heap compared to the stack makes it a more complex data structure with higher overheads for managing the items that it holds.
The heap
The purpose of the heap is to store data that needs to outlive specific methods. This means the heap is used to store reference type variables, which are referred to as objects. The garbage collector (GC) is a program that manages the objects on the heap, it allocates objects and reclaims objects that are no longer being used - freeing memory for future allocations. The GC frees programmers of these memory management responsibilities, however the details of the workings of the GC are complex and outside the scope of this post.
Thinking about variables and program memory
Up to now I have mentioned that the stack stores local variables and the heap stores reference type variables (i.e. objects), whilst this is true, it overgeneralizes the situation somewhat. Let's take a step back and think about what variables actually are and exactly how they're managed in memory.
A computer program has memory allocated to it by the OS that is used to hold the data that the program uses (i.e. to store variables) and other things. A key aspect of a program's memory is that it's divided into different parts that have different functions. For the purposes of this blog post we can think of that memory as being divided into three different parts: the stack, the heap, and everything else in the program's memory (like the program's machine instructions).
The stack and the heap store the values of the program's variables – i.e. they store the configuration of bits that a variable refers to. Thinking in this way: a variable is essentially an association between a name in the source code and a block of memory which either lives on the stack or the heap, with the contents of the block (some configuration of bits) being the value of the variable.
Each C# variable has a specific type, and the contents of the memory block associated with a given variable depend on its type. C# variables fall into two distinct type categories – value types and reference types, which are handled differently in memory. The type of a variable – specifically whether it's a reference or value type – and the context in which it was declared, determine whether it is stored on the stack or heap.
Let's quickly run through reference and value types in C#…
Value types vs reference types
Reference types
The value of a reference type is a reference (or null), meaning the value of a reference type is the memory address of the object to which it refers. So, a reference type variable does not hold the value of the object it refers to, it holds a reference to that object.
Car car = new Car("bmw");

The variable car in the code snippet above is a reference type, since its type is Car which is a user-defined class. The memory block that car is associated with contains a reference (a memory address) to a Car object.
Value types
A value type variable does hold the value to which it is associated.
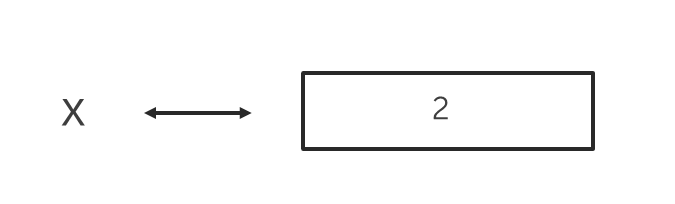
The example below shows a variable, x, of type int (a value type) and value 2. The block of memory associated with x therefore contains the integer 2 (i.e. its binary representation), as shown in the diagram below.
int x = 2;
So where do C# variables get stored?
Here, I'll first state the general rules (there are exceptions that I'll mention later) for determining where variables are stored in memory, then I'll provide some examples to help elucidate those rules.
Again: C# variables are stored on either the stack or heap, which one depends on whether the variable is of reference or value type, and on the context in which the variable is declared.
- Local variables (i.e. those that are declared inside methods) are stored on the stack. This means their values are stored on the stack, therefore meaning that local reference type variables have references stored on the stack and local value type variables have actual values stored on the stack.
- Objects of reference type variables (i.e. the things that references point to) always live on the heap.
- Instance variables that are part of a reference type instance (e.g. a field on a class) are stored on the heap with the object itself
- Instance variables that are part of a value type instance are stored in the same context as the variable that declares the value type. This means that a variable of a struct that is declared in a method will live on the stack, whilst a variable of a struct that is declared inside a class (i.e. a field on the class) will live on the heap.
Examples
Let's run through some examples to see how these rules play out in practice. I have included a diagram with each example showing where the various variables from the accompanying code snippets live in the program's memory.
Example 1
We're going to use the following Car class:
public class Car
{
public string manufacturer;
public int price;
public Car(string manufacturer, int price)
{
this.manufacturer = manufacturer;
this.price = price;
}
}
This is a basic class with two fields that are being initialised by a constructor.

static void Main(string[] args)
{
int price = 20000;
Car testCar = new Car("Audi", price);
}
In the Main method of this example we're declaring and initializing a local variable, price, of type int (value type), we're then declaring a variable of type Car (reference type), testCar, and initializing it with a reference to a Car object. price is a local variable of value type, therefore it will live on the stack; testCar is a local variable of reference type, therefore it will live on the stack, but, again, it's a reference type and so the thing stored on the stack is a reference (i.e. a memory address), as depicted in the diagram above. The actual Car object that the reference in testCar points to lives on the heap.
Let's go through step-by-step what's happening as this code runs. We get a block added to the stack to hold the variable price, and then another to hold testCar; these are both declared in the Main method and so are contained within its stack frame. Now, when the right-hand side of Car testCar = new Car("Audi", price) runs, the constructor to the Car class runs, which is a method and so a new stack frame is added to the stack to hold the variables for that method. The Car constructor is being called with the price variable as an argument for the price parameter, therefore the int value from price (in Main stack frame) is getting copied into the price variable in the Car stack frame (method parameters are local variables too); there is also the manufacturer parameter on the constructor, which is being passed a new string instance directly inside the call to the Car constructor, therefore there is a variable, manufacturer, of type string on the stack, living in the Car stack frame. The Car constructor then copies the values of these two variables from the Car stack frame into the corresponding fields on the Car object on the heap (as defined in the definition of the Car constructor show earlier).
The diagram above depicts the state of the stack and heap immediately after the program has executed the lines of code in the Car constructor method, but hasn't yet passed the closing curly brace of that method. Once the closing curly brace is passed, the stack frame associated with the Car constructor is removed from the stack, and we're left with the Main method's stack frame and the heap block containing the Car object.
The value of the manufacturer variable within the Car object is actually displayed incorrectly in the above diagram: the variable is of type string, which is a reference type, therefore manufacturer will hold a reference to a string object somewhere else on the heap (which will in-fact be a collection of char objects).
The amount of memory that the Car object occupies on the heap is equal to the amount of memory occupied by the members it contains – an int and a string reference – plus the memory occupied by the header, which all C# objects have.
In the following examples I'm going to ignore constructor methods as the diagrams get quite messy.
Example 2
For this next example I'm going to define a struct type, NumberOfSeatsAndDoors, and alter the Car class so that it holds a field of this type.
public class Car
{
public string manufacturer;
public int price;
public NumberOfSeatsAndDoors numberOfSeatsAndDoors;
public Car(string manufacturer, int price, NumberOfSeatsAndDoors numberOfSeatsAndDoors)
{
this.manufacturer = manufacturer;
this.price = price;
this.numberOfSeatsAndDoors = numberOfSeatsAndDoors;
}
}
public struct NumberOfSeatsAndDoors
{
public int numSeats;
public int numDoors;
public NumberOfSeatsAndDoors(int numSeats, int numDoors)
{
this.numSeats = numSeats;
this.numDoors = numDoors;
}
}
class Program
{
static void Main(string[] args)
{
NumberOfSeatsAndDoors x = new NumberOfSeatsAndDoors(5, 4);
Car testCar1 = new Car("Audi", 20000, x);
Car testCar2 = testCar1;
}
}
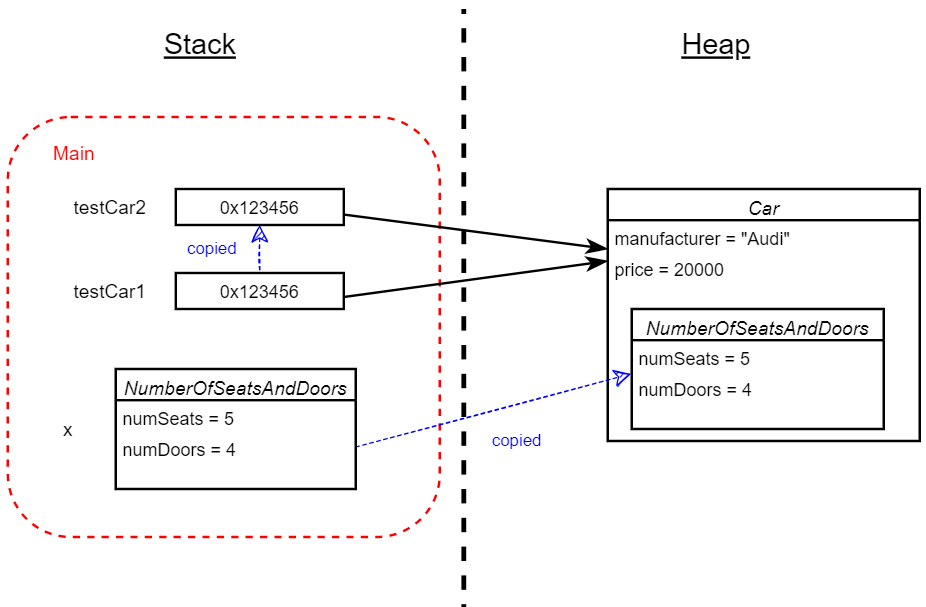
In the Main method of this example we're creating an instance of the struct type NumberOfSeatsAndDoors and assigning it into variable x, which is a local variable of value type and will therefore live on the stack.
Next, we're creating an instance of Car and assigning it into the local variable testCar1, this is a local variable of reference type and will therefore live on the stack and contain a reference to the Car object, which lives on the heap. To build the Car object, the variable x is being passed to the constructor; x is a value type and therefore its value – a NumberOfSeatsAndDoors instance - will be copied from the stack into the numberOfSeatsAndDoors field on the Car object, as depicted by the blue arrow in the diagram above.
Finally, another variable of type Car, testCar2, is being declared and initialised with the value of testCar1. These two variables are reference types, therefore the reference that testCar1 holds is being copied into the testCar2 variable, resulting in them both referring to the same Car object on the heap.
As in the previous example, the value of the local variables manufacturer and price have been copied from the Car constructor's stack frame into the appropriate fields on the Car object on the heap. The diagram above depicts the state of things after the final line of code in Main has executed, but before the closing curly brace has been passed, so at this point the stack frame corresponding to the Car constructor has been removed from the stack.
Note: in addition to ignoring the call to the constructor method of the Car class in this example, it's worth saying that the struct NumberOfSeatsAndDoors also has a constructor, therefore in reality there would be an additional stack frame added to the stack when this gets called - I have chosen to exclude this here too.
Example 3
For this example I'm going to add a static method to the Program class and use it in the Main method, I'm also going to revert back to the Car class from the first example - without the NumberOfSeatsAndDoors type field - to keep things simple.
public class Car
{
public string manufacturer;
public int price;
public Car(string manufacturer, int price)
{
this.manufacturer = manufacturer;
this.price = price;
}
}
class Program
{
static void Main(string[] args)
{
int price = 20000;
Car testCar = new Car("Audi", price);
InreaseCarPrice(testCar, 5000);
}
static void IncreaseCarPrice(Car car, int priceIncrease)
{
car.price += priceIncrease;
}
}
The IncreaseCarPrice method, takes two parameters, car and priceIncrease, and simply alters the price field on car (a Car object) by increasing its value by the value of priceIncrease.
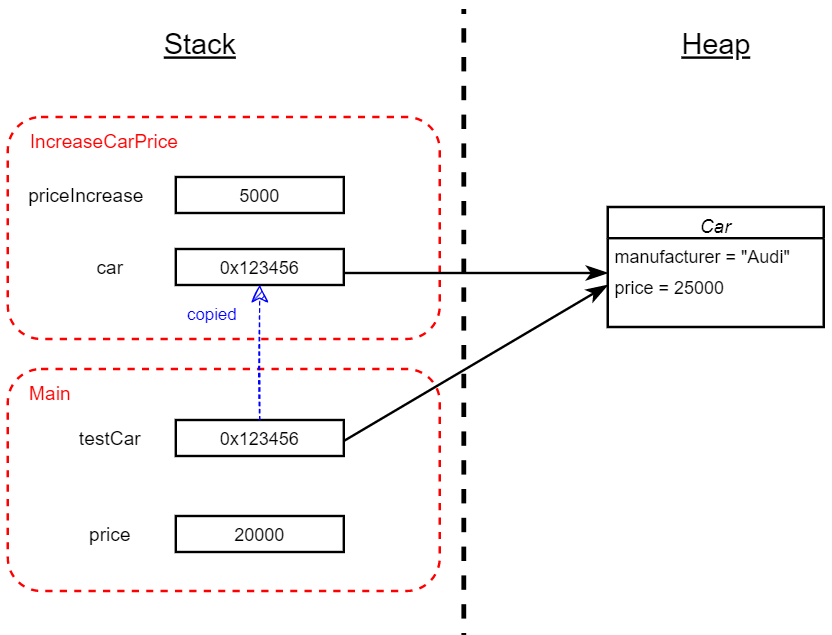
As before, we're creating an int and assigning it into a local variable price, and declaring a variable, testCar, and initializing it with a reference to a Car object, both of these variables live on the stack, whilst the Car object lives on the heap. (Again, I'm choosing not to talk about the Car constructor here, and the copying of values to/from the constructor's stack frame).
Next, we're calling the IncreaseCarPrice method, which results in a new stack frame being pushed onto the stack to contain the local variables of that method. testCar is being passed as an argument for the car parameter, meaning the reference that it holds is being copied into the local variable car in the stack frame of the IncreaseCarPrice method; a new int of value 5000 is being created and assigned into the priceIncrease parameter. As a result, the stack frame associated with IncreaseCarPrice contains an integer with value 5000 and a reference pointing to a Car object on the heap. The line of code in the IncreaseCarPrice method is then being executed which changes the price field on the Car object on the heap.
When the program reaches the closing curly brace of the IncreaseCarPrice method, the corresponding stack frame is popped off the stack, resulting in the earlier stack frame - corresponding to the Main method - being at the top and its contents being in scope. Therefore the diagram above is depicting the state of things at the point in time after the line of code in IncreaseCarPrice has been executed, but before the closing curly brace on that method has.
There are exceptions
What I have described up to now are the general rules for determining where a C# variable gets stored in memory. However, this is not the full story – there are some exceptions, I'll talk briefly about some of them now.
Static variables
Static variables always live on a heap, and there's only ever a single heap block that holds the value of the variable. This makes sense when you think what static variables are: there's a single object that the variable refers to which needs to outlive the method in which it was declared. However, notice I said a heap, not the heap; there are in-fact multiple heaps and it's possible that a static variable may not be allocated on "the heap" (i.e. the managed heap).
Captured variables
Anonymous functions, which include lambda expressions, complicate matters slightly. When you declare an anonymous function, it has access to the local variables from the containing method, these are called captured variables. The compiler enables this by generating a class to hold any of the local variables from the containing method that the anonymous function uses, it creates an instance of this class inside the containing method and copies the required local variables into fields on that object. The code inside the anonymous function then uses the fields on that class. In other words, some variables that appear to be local variables (i.e. live on the stack) of anonymous functions are in fact fields of an object living on the heap.
This can also be true of local functions (methods defined in other methods). If you define a delegate that refers to a local function, the compiler will capture the variables from the containing method in the same way.
Asynchronous methods and iterators
Asynchronous methods return before completing to allow the calling method to continue executing whilst something time consuming takes place. At some point the asynchronous methods resumes execution, which means the state inside the method at the point in time at which it returned needs to have been preserved, even though it returned. Therefore the stack frame associated with an asynchronous method cannot be deallocated in the way I described when the method returns to work asynchronously; the compiler has to do some work to achieve this.
This also applies to iterators – iterators and async methods share similar implementation details.